Dynamics 365 Customer Insights is a platform that allows you to combine customer data from several sources into a single view. This unified data is a great place to start when creating bespoke machine learning (ML) models to create important business indicators. We saw how to use Azure Machine Learning (AML) Studio to create custom ML models that operate with the unified data from Customer Insights in a previous article. We provide AML Studio–based model pipelines for three often encountered use cases to speed up the initial model development:
Dynamics 365 Customer Insights is a platform that allows you to combine customer data from several sources into a single view. This unified data is a great place to start when creating bespoke machine learning (ML) models to create important business indicators. We saw how to use Azure Machine Learning (AML) Studio to create custom ML models that operate with the unified data from Customer Insights in a previous article. We provide AML Studio–based model pipelines for three often encountered use cases to speed up the initial model development:
- Customer lifetime value (CLTV)
- churn analysis
- Productrecommendations
In this blog, we’ll go through these models in further depth.
Incident at a Hotel
The models in this post will be based on the Contoso Hotel scenario. CRM data is collected at the Contoso Hotel and consists of hotel stay activities. The information regarding the dates of stay for each registered consumer is stored in this data. The data also includes information on the booking, room kinds, and spending details, among other things. From January 2014 to January 2018, the data covers roughly four years.
Customer profiles provide the second set of data. Each customer’s personal information has been stored in these profiles since they were originally registered with the hotel or since their first visit. Name, birth date, postal address, gender, phone number, and other details are included. The hotel’s additional services are included in the third set of data. For example, spa services, laundry services, Wi-Fi, courier services, and so on. Each registered customer’s information is likewise logged. The typical usage of services is associated with a stay, although it is not essential; in some circumstances, consumers can utilize services without being in the hotel.
Analyze the Churn
Churn analysis may be used in a variety of scenarios (e.g., retail churn, subscription churn, service churn, etc.). We’ll look at service churn in this case, especially in the context of hotel services, as indicated above. The model will give insights into all the phases in constructing a custom model using Azure ML and Customer Insights, even if it does not explicitly cover all of the cases. It will also provide a functioning example of an end–to–end model pipeline that can be used to create any other sort of churn model.
Churn is a word that has several meanings.
Depending on the situation, churn can be defined in a variety of ways. In the instance of hotel activities, our definition is that a client should be categorized as churned if he or she has not visited the hotel in the previous year.
The AML Studio experiment may be imported from the gallery, as mentioned in our previous blog. The import blocks that read these tables from the Azure blob storage location are shown below.

Featurization
We start by identifying the raw characteristics that will have some causal influence or impact on the label, based on the concept of churn. Then we convert this raw information into numerical features that may be used in machine learning models. As a result of the data integration in Customer Insights, linking these tables is as simple as utilizing the “Customer ID” produced by Customer Insights.
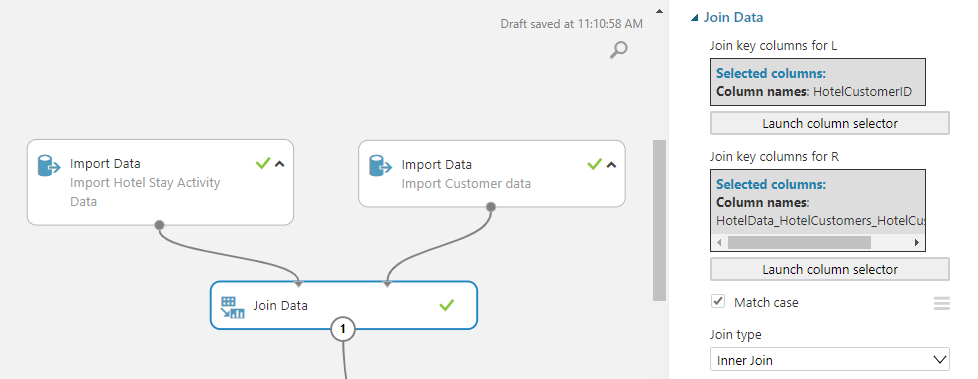
The featurization for churn analysis model construction can be a little hard. The topic is commonly framed as a static task, such as picture classification, yet the underlying data is not static, unlike a set of photographs. The information is time-based, with new hotel activities being logged on a daily basis. As a result, featurization should account for this and build static features from dynamic data. In this scenario, we use a one-year sliding frame to derive several characteristics from hotel activities. We also use one-hot encoding to break out category variables like room type and booking type into independent features.
The following is the complete list of features:
| Number | Original_Column | Derived Features |
| 1 | Room Type | RoomTypeLargeCount, RoomTypeSmallCount |
| 2 | Booking Type | BookingTypeOnlineCount, BookingTypePhoneCallCount |
| 3 | Travel Category | TravelCategoryBusinessCount, TravelCategoryLeisureCount |
| 4 | Dollars Spent | TotalDollarSpent |
| 5 | Check-in and Checkout dates | StayDayCount, StayDayCount2016, StayDayCount2015, StayDayCount2014, StayCount, StayCount2016. StayCount2015, StayCount2014 |
| 6 | Service Usage | UsageTenure, ConciergeUsage, CourierUsage, DryCleaningUsage, GymUsage, PhoneUsage, RestaurantUsage, SpaUsage, TelevisionUsage, WifiUsage |
choosing a model
The next step is to determine the best algorithm to utilize after the feature set is complete. The majority of the characteristics in this scenario is categorical traits. Typically, decision tree–based models do well in such scenarios. Neural networks may be a superior alternative for solely numerical characteristics. In such cases, the support vector machine (SVM) is also a strong contender; however, it requires a lot of tuning to get the best results. The first model we chose is “gradient boosted decision tree,” followed by SVM as the second model. AML Studio allows you to compare and contrast two models via A/B testing. It’s usually advisable to start with two models rather than one to get the most out of this.
AML Studio’s model training and assessment process is depicted in the diagram below.
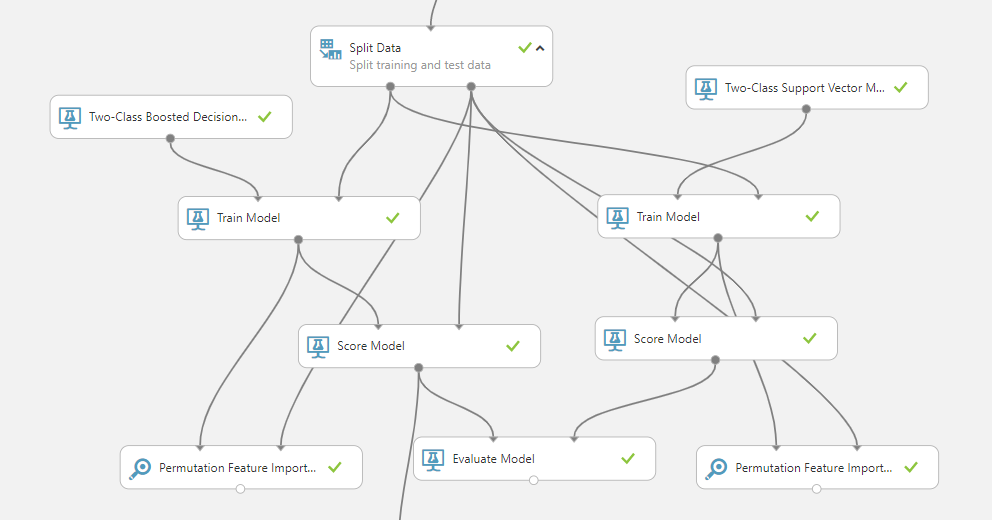
In addition, we use a method known as “Permutation Feature Importance.” This is an important feature of model optimization. All of the built-in models are black box models that provide little to no insight into the influence of any one element on the final forecast. The feature relevance calculator employs a unique method to calculate the impact of various characteristics on a model’s ultimate conclusion. The relevance of each attribute is scaled from +1 to -1. The negative impacts imply that the related features have an illogical effect on the outcome and should be eliminated from the model. A higher positive effect means the characteristic is making a significant contribution to the forecast. These numbers should not be confused with correlation coefficients because they are two separate measures.
completing the Customer Insights integration
We may develop a predictive service as mentioned in the previous blog after the training experiment is completed and the generated metrics are satisfactory.
Ascertain that the projections are accompanied with the Client Insights customer IDs. The predictions may then be exported to the same blob storage and re-imported into Customer Insights.
Prediction of customer lifetime value (CLTV)
The computation of customer lifetime value (CLTV) is one of the most important measures that a company may use to evaluate and classify its customers. Knowing your consumers is crucial in the hotel industry. Understanding the difference between guests who add value and those who don’t, for example, may give critical information to hotel management. This form of segmentation can aid hotel management in determining which elements they should priorities and develop in order to please their high-paying clients against less critical characteristics. These choices can have a significant influence on sales and profits. The CLTV will be defined in this case as the total money brought in by the client throughout the specified time period.
CLTV’s definition
The CLTV of a client as of today will be defined as the total dollar amount the customer is likely to spend in the next 365 days or 1 calendar year. To forecast this figure, we’ll utilise data from all consumers over the last three years.
Featurization
The featurization will be quite similar to the churn scenario in this case; however, the label and projected values will be different than those stated previously.
Selection and training of models
Because the projected value is a positive valued continuous variable, predicting the CLTV is a regression issue. We use Boosted Decision Tree Regression as one approach and Neural Network Regression as another to train the model based on the feature attributes.
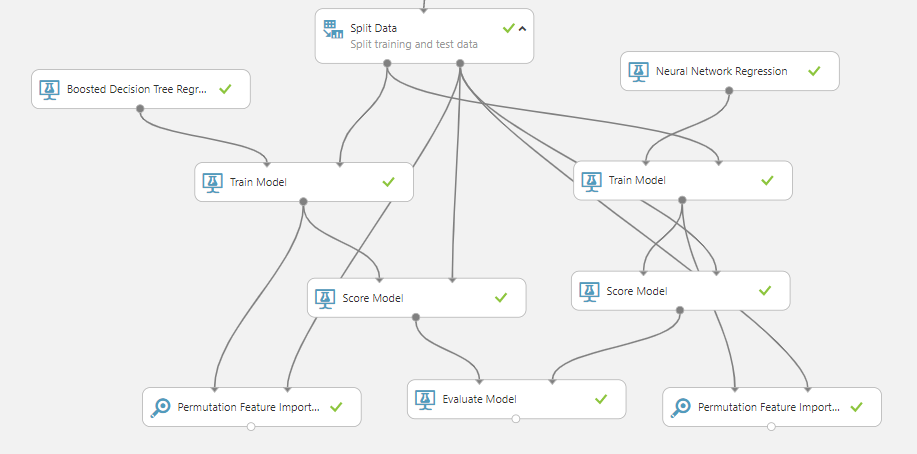
completing the Customer Insights integration
The output of the CLTV model is attached to Customer IDs and fed back into Customer Insights for additional analysis, as outlined in the churn model.
Next Best Action or Product Recommendation
In the context of a hotel, product recommendation is recommending to consumers the hotel’s services. The goal is to match clients with the right services so that their consumption is maximized. The issue is comparable to that of video streaming service consumers receiving movie suggestions.
Definition of Next Best Action or Product Recommendation
The aim is to maximize the dollar amount of service usages by providing hotel clients with the finest matched services based on their interests.
Training and Featurization
We’re combining the hotel ServiceCustomerID with Customer ID in a similar way to the churn model in order to produce consistent recommendations per Customer ID.
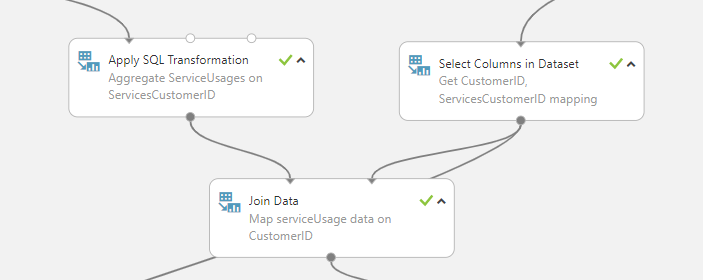
The data is obtained from three separate sources, as stated earlier, and characteristics are extracted from them. When compared to churn or CLTV situations, the featurization for the problem of recommendation is different. Three sets of features are required as input data for the recommendation model. The first set of features reflects the customers’ prior usage of services, the second set contains the specifics of each service, and the third set represents the customers’ information.
To train the recommendation model, we utilize the Matchbox Recommender algorithm.
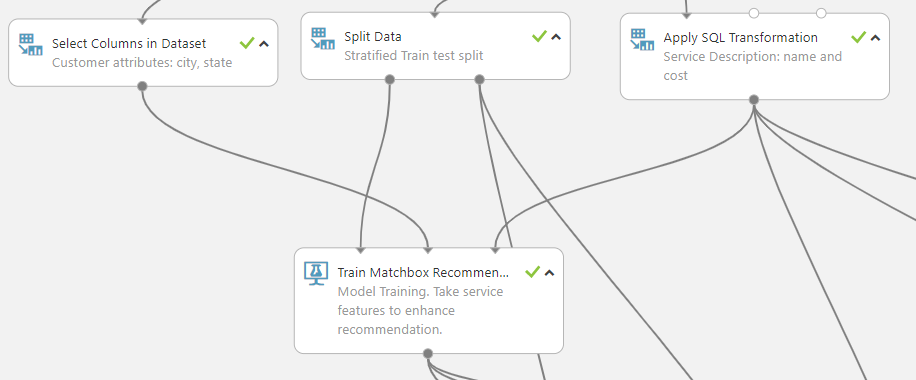
The Train Matchbox Recommender model accepts three input ports: training service usage data, customer description (optional), and service description, as shown in the diagram above. The model may be scored in three distinct ways. One is for model evaluation, which involves computing an NDCG score to rank the assessed elements. The NDCG score in this trial is 0.97. Depending on the business requirement, the model can be scored on the full recommendable service catalogue or solely on products that consumers have never used before.
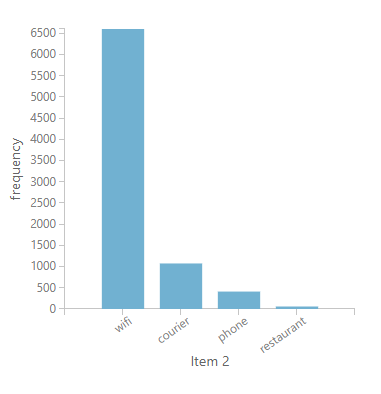
Looking at the distributions of the recommendations over the full-service catalogue, we see that the top services to be suggested are phone, Wi-Fi, and courier. This is in line with what we discovered from the service usage data distributions: